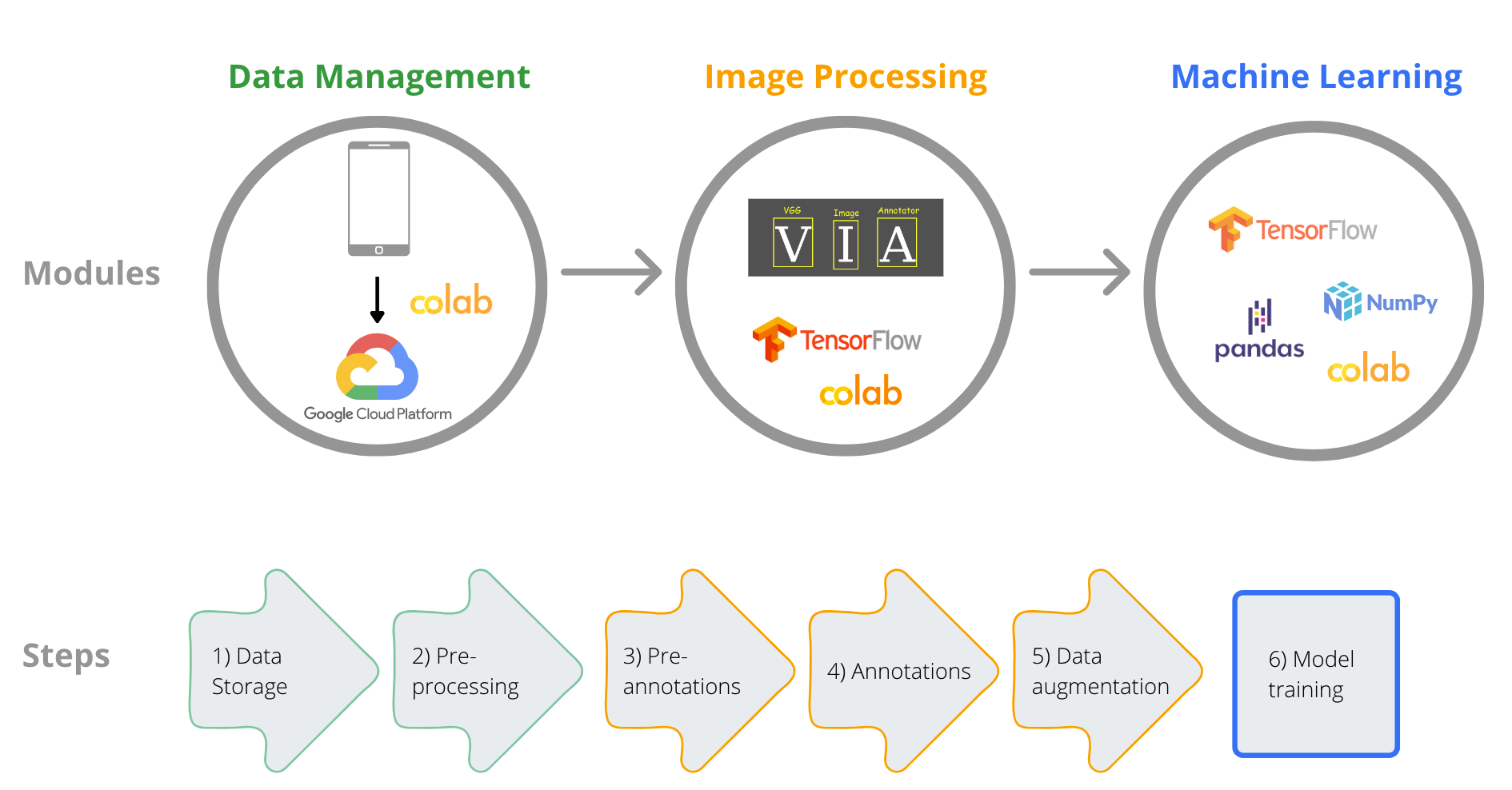
Dirbtinio intelekto modelis žuvų rūšių atpažinimui
Įvadas
Čia pristatome vartotojui draugišką ir lengvai pritaikomą dirbtinio intelekto (DI) sistemą, skirtą žuvų rūšių identifikavimo modeliams kurti. Parengėme duomenų pirminio apdorojimo, vaizdų apdorojimo ir mašininio mokymosi modelių kūrimo kursą ir kodus, kuriuos galite rasti mūsų rengtuose nuotiniuose mokymuose.
Šiame atviros prieigos straipsnyje skelbtame žurnale Sustainability rasite išsamų sistemos aprašymą, bandomąjį pavyzdį, kuriame demonstruojamas galimas panaudojimas mėgėjiškos žvejybos tyrimams, žinių, įgytų taikant pavyzdį, santrauką ir pagrindinių uždavinių bei galimo tolesnio plėtojimo apžvalgą. Visus sistemoje naudojamus kodus taip pat galite rasti mūsų Github puslapyje.
Modelio kodas
Norint naudoti mūsų modelius, labai svarbu, kad žuvų rūšys (arba ekotipai, arba bet kokios kitos klasės, kurias norite, kad jūsų modelis identifikuotų) jūsų duomenų rinkinyje būtų identifikuotos teisingai, kitaip jūsų modelis bus netikslus. Nuotraukas (JPEG arba PNG formatu) galite įkelti į “Google” diską pagal rūšis (t. y. po vieną rūšį viename aplanke - įsitikinkite, kad jos yra teisingai identifikuotos), laikydamiesi šios katalogų struktūros:
dataset
|__ eserys
|______ eserys1.PNG
|______ kita_nuotrauka.PNG
|______ ...
|__ lydeka
|______ nuotrauku_pavadinimai_nesvarbus.PNG
|______ dar_viena_lydeka.PNG
|______ ...
|__ kuoja
|______ 10250198.PNG
|______ bet_koks_pavadinimas.PNG
|______ ...
|__ ...
Šis modelis sukurtas “Python” kalba ir veikia nemokamoje “Google Colab” versijoje. Pateikiami programiniai kodai yra pritaikyti taip, kad juos būtų patogu naudoti ir jų naudojimui nereikėtų išsamių “Python” programavimo kalbos žinių (tačiau norint toliau kodus pakeisti, tam tikos programavimo žinios žinoma yra reikalingos).
“Colab”, arba “Colaboratory”, yra nemokama, į “Jupyter” tinklo aplinką panaši debesų kompiuterijos aplinka, leidžianti vykdyti “Python” kodą (ir “Python” bibliotekas) naršyklėje be atskiro įdiegimo ir konfigūravimo. Ji taip pat suteikia prieigą prie riboto kiekio skaičiavimo išteklių.
Norėdami pradėti naudotis “Google Colab”, turite turėti “Google” paskyrą. Žemiau pateikta nuoroda nukreips jus į “Google Colab” užrašų knygelę. Ji atvers užrašų knygelę, kurią galėsite paleisti ir keisti tiesiogiai (t. y. nesirūpindami, kad perrašysite šaltinį ar pradinę užrašų knygelę). Norėdami išsaugoti bet kokius užrašų knygelės pakeitimus, turėsite išsaugoti užrašų knygelės kopiją savo “Google” diske. Jei bandysite įrašyti pakeitimus tiesiogiai pradinėje užrašų knygelėje, gausite pranešimą “cannot Save changes” (negalima įrašyti pakeitimų) ir turėsite pasirinkti “Save a copy in Drive” (įrašyti kopiją diske).
Pakeitę užrašų knygelę galite išsaugoti pakeitimus pasirinkę File→Save a copy in Drive (Failas→Įrašyti kopiją diske) ir vadovaukitės gautais nurodymais.
Taip pat galite sukurti naują užrašų knygelę nuėję į “Google Colab” pagrindinį puslapį čia ir spustelėdami apatiniame dešiniajame kampe esančią nuorodą “new notebook”. Jei norite, taip pat galite spustelėti “atšaukti” ir pereiti prie trumpo mokomojo vadovo, kaip pradėti dirbti su “Google colab”.
Taip pat atkreipkite dėmesį, kad šiame užrašų sąsiuvinyje pateikiame trijų žuvų rūšių duomenų rinkinio pavyzdį, kurio nuotraukas pateikė Kanados žvejų piliečių mokslo programa **My Catch, Angler’s Atlas, bendradarbiaujanti su Gamtos tyrimų centro mokslininkais.
Norėdami taikyti mūsų modelį, galite naudoti šį kodą:
![]()
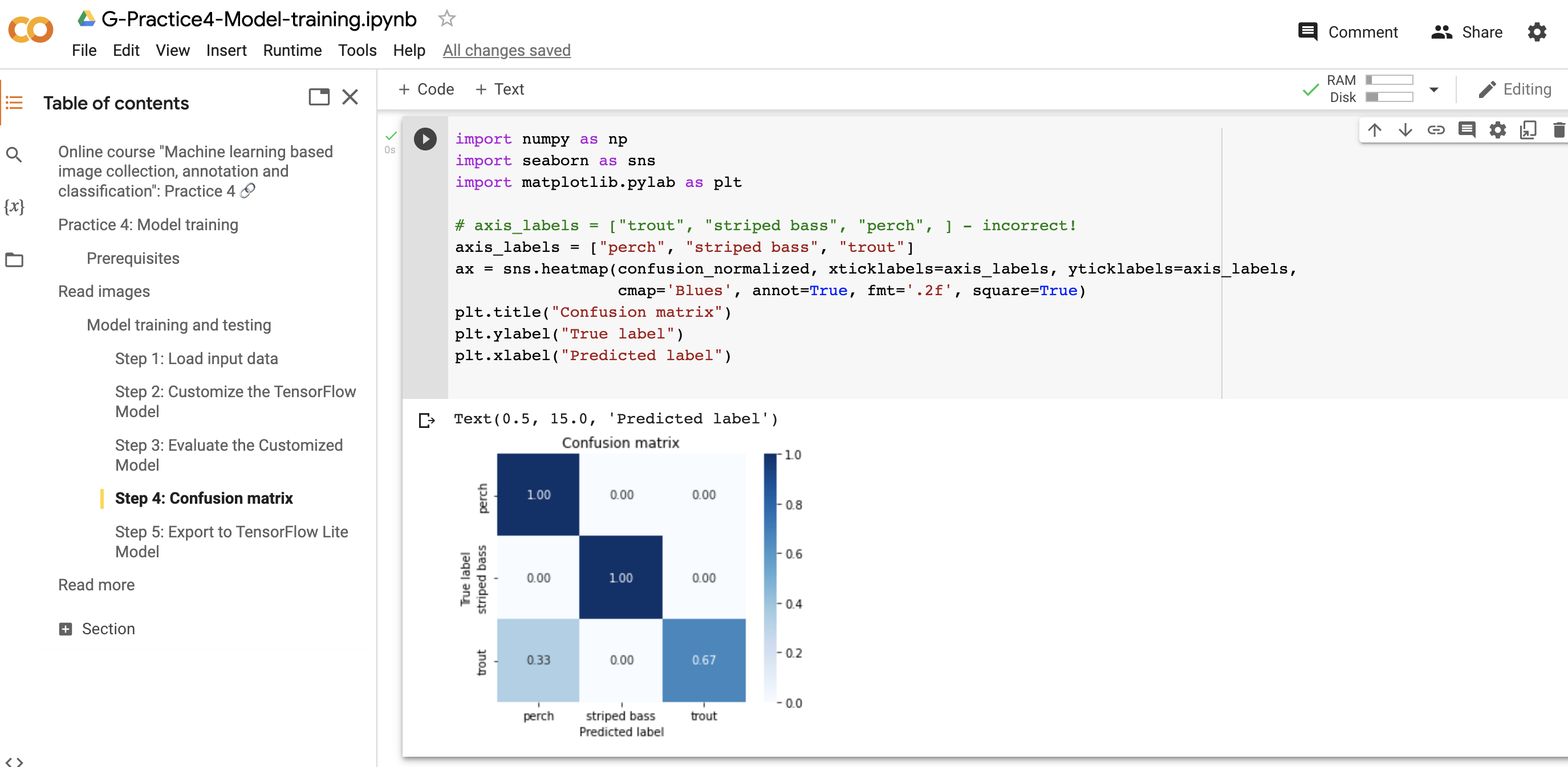
Modelio taikymas
Jei norite daugiau sužinoti apie modelio vystymą ir pritaikymą galite peržiūrėti šį pranešimą nuotoliniame seminare “Internetinis seminaras:”Mašinų mokymasis, žvejyba ir piliečių mokslas” arba šį pranetimą nuotoliniame seminare “Mėgėjiškos žvejybos pastangos ir įsitraukimas skaitmeniniame amžiuje”.
Šiame atviros prieigos straipsnyje mes detaliai aprašome kaip pristatymas metodas gali būti taikomas mėgėjiškos žūklės tyrimams. Visų pirma parodome mokslinį taikymą, naudingumą ir mastelio didinimo galimybes žuvų rūšims ar kitiems objektams klasifikuoti. Čia pateikta sistema yra lanksti, ją galima pritaikyti įvairiems vaizdų klasifikavimo ir mokslinių tyrimų klausimams spręsti. Parodome, kad turint palyginti nedidelį vaizdų skaičių kiekvienoje vaizdų klasėje (200-300), galima greitai ir su minimaliais ištekliais sukurti gana aukšto našumo modelį nedideliam klasifikavimo klasių skaičiui (mūsų atveju - šešioms).
Tolimesniam modelio vystymui ir taikymui kviečiame ir skatinsime platesnį mokslininkų bendruomenės ir piliečių mokslo įsitraukimą. Tyrimų grupės visame pasaulyje galėtų įtraukti vietinius piliečius mokslininkus, kad jie rinktų nuotraukas mažų modulinių modelių, susijusius su vietos žuvininkystės valdymo ir ekologiniais klausimais, kūrimui. Tokie modeliai leistų greičiau apdoroti naujus piliečių mokslo duomenis, ir tai žymiai padidintų mėgėjiškos žvejybos tyrimams prieinamų duomenų kiekį.
