Machine learning based image collection, annotation and classification

In this online course you will learn about:
- concepts of data science, machine learning (ML), computer vision, deep learning and Convolutional Neural Networks (CNNs)
- how to pre-process and pre-annotate images to accelerate your ML projects
- how to apply data augmentation techniques
- how to build an image classification model with your own or example data
The online course will be organised as a series of recorded lectures and exercises using Python, combined with live Q&A sessions.
The course is led by Catarina Silva (Nature Research Centre, Lithuania) and Asta Audzijonyte (Nature Research Centre, Lithuania & University of Tasmania, Australia).
Participation is free. If you would like to participate, please register here.
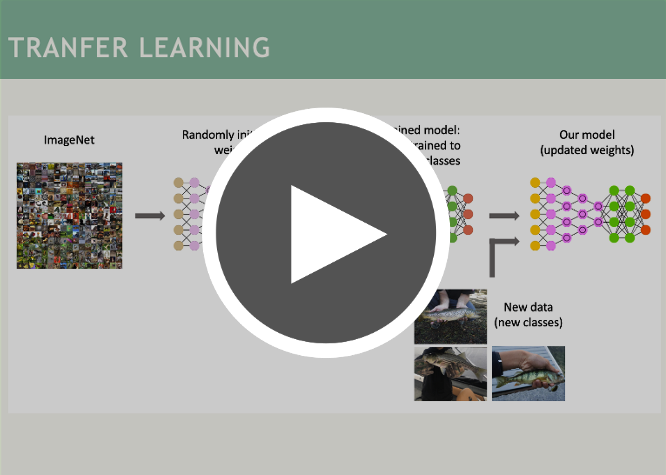
This course is using the framework described in this publication.
Course overview
A. Introduction
B. Concepts of machine learning and computer vision
C. Intro Practice: Basics of computer vision with Python
D. Practice 1: Pre-processing images
E. Practice 2: Images pre-annotation and annotation
F. Practice 3: Data augmentation
H. Ideas for the future (will be released after the course)
Programming skills and Python
It will be useful if course participants have basic programming experience, in Python or R. The scripts used in the course are written in Python, but they are adapted to be user friendly and do not require prior Python knowledge to run them (you would naturally need Python knowledge to modify these scripts further). If you want to learn more about coding with Python a few useful tutorials of basic operations can be found here. You can also find a list of books here.
Bring your own images
We will provide an example dataset for the course. This dataset includes 50 images per species which were provided by MyCatch and Fishial. It would be very interesting and exciting if course participants also bring their own datasets of fish images. We would need a minimum of 50 images per species and you can use as few as 2 species to start with (however, if species are very similar morphologically, we might need more than 50 images per species). Of course, you want to make sure that fish species in your dataset are identified correctly, otherwise your model will not be very useful (you might have heard the expression “garbage in - garbage out”). Finally, for the tutorials we will use Google drive so please upload your own images to your Google drive by species (i.e. one species per folder).
Online meetings
In this course, it is expected that participants will mostly learn independently, but we will have three online meetings to go through the materials, ask questions and for general discussion.
These meetings will be recorded and videos will be available (below) immediately after the meeting.
| Date | Time (GMT+1) | Programme |
|---|---|---|
| 25 Oct, 2022 | 09:00 | Welcome and introductions, overview of modules A-D, Q&As |
| 26 Oct, 2022 | 12:00 | Q&As, overview of modules E-F |
| 27 Oct, 2022 | 15:00 | Q&As, overview of module G, presentation of trained models and future directions |
Meeting 1

Meeting 2

Meeting 3

This course is organised as a part of the “Sustainable inland fisheries” project, funded by the European Regional Development Fund (project No 01.2.2-LMT-K-718-02-0006) under grant agreement with the Research Council of Lithuania (LMTLT).