Course Overview > Intro Practice: Basics of computer vision with Python
Intro Practice: Basics of computer vision with Python
This course uses a computer vision and ML image analysis framework described in detail in this publication.
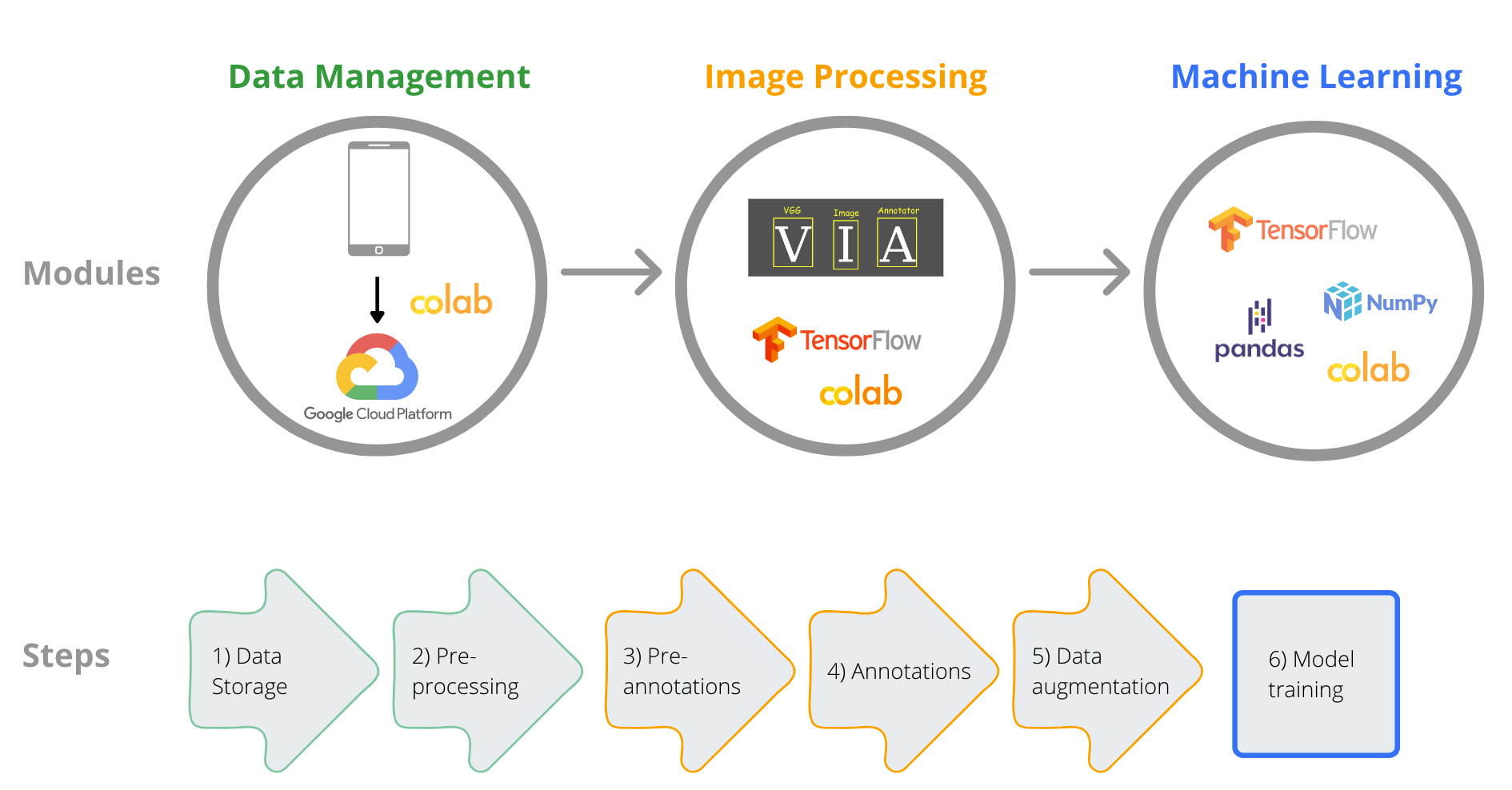
This open-source modular framework for large scale image storage, handling, annotation and automatic classification, uses cost- and labour-efficient methodologies. The tool is based on TensorFlow Lite Model Maker library and includes data augmentation and transfer learning techniques, applied to different convolutional neural network models (see session on concepts of this course).
In the introductory practice below we will use Python and computer vision libraries for basic image processing. We will learn to mount data on our Colab runtime, read an image, get information about its dimensions and shape and understand the basic idea of how image information is read by computers. You will learn that computers store images as 2D or 3D matrices, depending on whether it is a gray scale or a colour image. While many of these steps are done automatically in many libraries (R language) and modules (Python), it is nevertheless useful to get a basic idea of how computers ‘see’ and handle images.
We will also write a few simple Python functions to visualise images. You can just follow and execute the code, but if you would like to learn more about writing functions yourself, you can check some tutorials here.
One of the libraries we will use is this course is OpenCV. This library is used widely in computer vision, although we will only use a few basic functions to read and display images. If you would like to learn more about the library you can find a short online course here and several tutorials here.
The practice is done on Google Colab and you can access the notebook here:
![]()
The link above will take you to the notebook that will look like this:
Other Resources
Book : Programming Computer Vision with Python by Jan Erik Solem