Machine learning based image collection, annotation and classification of fish species
Introduction
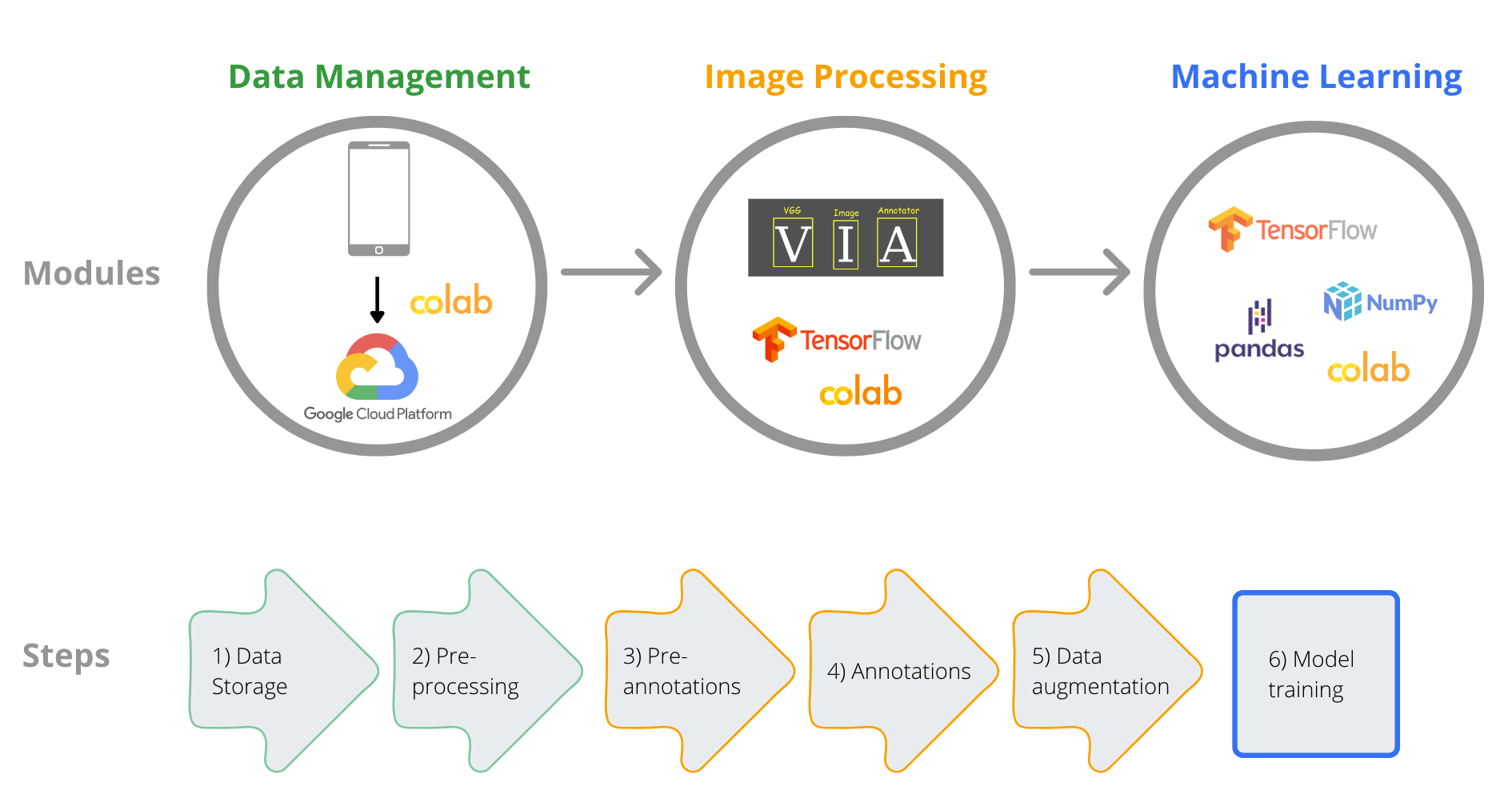
Here we present a scalable user-friendly artificial intelligence (AI) framework to develop fish species identification models. We have prepared a course and scripts for data pre-processing, image processing and machine learning model development, which you can find on our Online course webpage.
In this publication in the journal Sustainability you will find a detailed description of the framework, a pilot case-study where we demonstrate potential use for recreational fisheries research, a summary of the knowledge gained from the case study application and an outline of the main challenges and potential future development. You can also find all the scripts used in the framework in our Github page.
Model code
To use our models it is very important that fish species (or ecotypes or any other classes you want your model to identify) in your dataset are identified correctly, otherwise your model will not be very useful (you might have heard the expression “garbage in - garbage out”). You can upload images (in JPEG or PNG format) to your Google drive by species (i.e. one species per folder - please make sure these are correctly identified), following this directory structure:
dataset
|__ perch
|______ perch_fig1.PNG
|______ another_photo.PNG
|______ ...
|__ striped_bass
|______ photo_titles_do_not_matter.PNG
|______ another_striped_bass_photo.PNG
|______ ...
|__ trout
|______ 1268952.PNG
|______ or_any_random_name.PNG
|______ ...
|__ ...
This model is developed in Python and is run on a free version of Google Colab. Scripts provided are adapted to be user friendly and do not require prior Python knowledge to run them (but some Python knowledge is required to modify these scripts further).
Colab, or “Colaboratory”, is a free, cloud-based environment similar to Jupyter’s network environment that allows us to execute Python code (and Python libraries) in the browser without the need for installation and configuration. It also provides some free access to computing resources.
To start using Google Colab, you will need a Google account. The link below will direct you to the Google Colab notebook. It will open the notebook which you can run and modify directly (i.e. without worrying about overwriting the source or original notebook). To save any changes you make to the notebook you will have to save a copy of the notebook in your own Google Drive. If you try to save the changes directly in the source notebook you will get the message “Cannot save changes” and you need to select “Save a copy in Drive”.
After modifying your notebook you can save changes by choosing File→Save a copy in Drive and follow the resulting prompts.
Alternatively, you can start a new notebook by going to Google Colab’s home page here and clicking “new notebook” on the bottom right corner. If you like you can also click “cancel” and go to a short tutorial on how to get started with Google colab.
Please also note that in this notebook we provide an example data set with three fish species, with photos contributed by the Canadian angler citizen science platform **My Catch, Angler’s Atlas, through a collaborative data sharing agreement with Nature Reserach Centre.
To apply our model you can use this code:
![]()
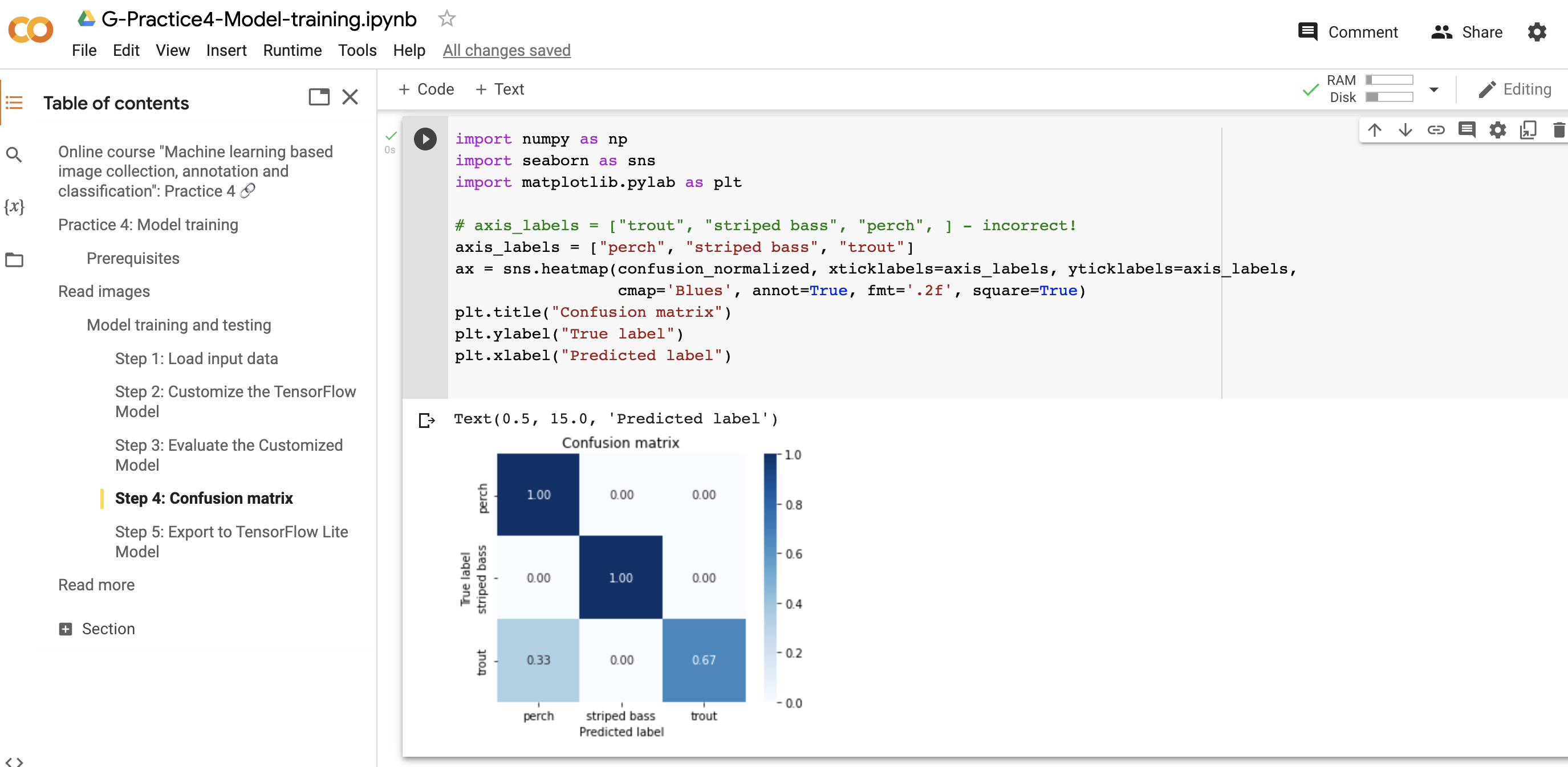
Application of the model
To learn more about the application of the model you can watch this talk for the “Online workshop: Machine learning, fishing and citizen science” and this talk for the “Online seminar: Recreational angling effort and engagement in the digital age” to learn more about this model.
In this publication we demonstrate the potential use of this approach for recreational fisheries research. In particular, we illustrate the scientific application, utility and potential for scalability for fish species or other object classification. The framework is flexible, and can be customised for a variety of image classification and research questions. We show that with a relatively small number of images per class (200–300), a model of reasonably high performance can be developed quickly and with minimal resources for a small number of classification classes (six in our case).
Contributions of the research community to fish species identification models would be especially powerful, as research groups around the world could engage local citizen scientists to assemble images and develop models relevant for local fisheries’ management and ecological questions. Such models could then enable faster processing of new local citizen science data, spearheading recreational fishing assessments into a new data-rich era.
